医疗AI靠谱吗?专家解读真相与误区
作为2024年服贸会重要组成部分之一,国家卫生健康委员会百姓健康频道(CHTV)定于9月13日在京举办“2024首都国际医学大会的平行论坛——数智医疗与医学人工智能创新论坛”,CHTV&金宝搏网站登录技巧 将为您带来AI赋能医疗的系列报道,今天我们就来聊一聊大型语言模型的临床应用现状与不足。
导语:作为2024年服贸会重要组成部分之一,国家卫生健康委员会百姓健康频道(CHTV)定于9月13日在京举办“2024首都国际医学大会的平行论坛——数智医疗与医学人工智能创新论坛”,CHTV&金宝搏网站登录技巧 将为您带来AI赋能医疗的系列报道,今天我们就来聊一聊大型语言模型的临床应用现状与不足。
01
医疗AI的现实挑战:从潜力到实践的无尽探索
在医疗领域,人工智能(AI)的引入被看作是提升医疗服务质量的关键。然而,尽管大型语言模型(LLM)在临床实践中的应用前景广阔,它们在实际应用中的表现却并非总能达到预期。2024年5月,斯坦福大学的Jenelle Jindal博士、Nigam Shah博士和同事们在一篇题为“Large Language Models in Healthcare: Are We There Yet? (医疗保健领域的大型语言模型:我们做到了吗?)”的文章中深入探讨了这一问题,指出了医疗AI在实现其临床价值方面存在的显著差距,并提出了对现有研究方法的深刻反思。
尽管LLM在理论上具有巨大的潜力,但在实际应用中,它们在回答患者问题时可能会出现错误或幻觉。例如, LLMs在一项研究中回答患者问题时出现了明显错误,这些错误在某些情况下甚至可能危及患者生命。这不仅暴露了医疗AI在安全性方面的不足,也强调了对这些模型进行严格评估的必要性。目前的研究往往依赖于精心设计的数据集,而不是基于真实的患者护理数据,这限制了我们对LLM在实际医疗环境中表现的全面理解。
此外,作者们强调了医疗AI与传统AI在部署上的本质区别。传统AI模型的更新迭代是有序的,而GenAI的快速发展和不断涌现的新能力,打破了这一有序的更新模式。这种快速的技术进步,虽然带来了新的可能性,但也带来了评估和实施上的挑战。为了实现GenAI在医疗领域的潜力,需要建立一套系统的评估框架。这一框架不仅需要涵盖技术层面的评估,还应包括对模型输出的伦理、法律和社会影响的考量。作者认为,借鉴计算机科学领域对基础模型的标准,可以为医疗AI的评估提供更为坚实的基础。
02
精准评估,解锁医疗AI潜力:精准导航临床应用之路
作者指出,在医疗AI领域, LLM的临床应用潜力正受到前所未有的关注。然而,现有研究多基于人工策划的数据集,如医学考试问题和案例摘要,而非真实患者护理数据。这种偏差限制了我们对LLM在实际医疗环境中性能的理解。例如,MedAlign研究中,医生对LLM生成的响应进行了评估,这些响应针对的是特定电子健康记录(EHR)中的临床指令。尽管这一过程耗时且评估医生间的一致性存在挑战,但它凸显了在真实患者数据上测试LLM的重要性。
在医疗任务的评估中,作者发现研究集中在特定领域,如通过美国医学执照考试(USMLE)等医学考试来增强医学知识,而对诊断和治疗建议的关注较少。这种集中趋势可能导致对非临床和行政任务的忽视,而这些任务在减轻医生工作负担方面具有潜在的更大影响。例如,LLM在加快临床试验患者招募方面的应用,可显著提升招募速度并降低成本,这一点在社区医院尤为关键,因为那里的资源较少,难以有效筛选适合参与试验的患者。
在评估维度的选择和优先级方面,作者指出除了准确性之外,还需要考虑公平性、偏见、有害性、稳定性以及部署时的考量等其他重要维度。LLM可能会在其输出中反映训练数据中的偏见,这在医疗领域尤其需要警惕。例如,一个LLM评估代理在评估1 300个响应时,展示了自动评估代理在检测可能延续种族刻板印象内容方面的潜力(表1、2)。这种评估工具的开发,如斯坦福大学的全面语言模型评估(HELM),为标准化评估提供了新的方向,确保了在医疗领域中对所有重要评估维度的全面考虑。
表1 评估维度定义精确度
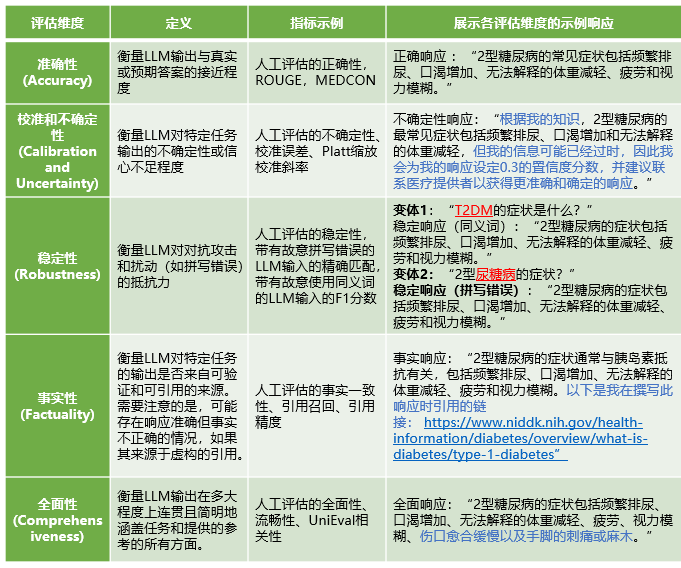
表2 其他评估维度
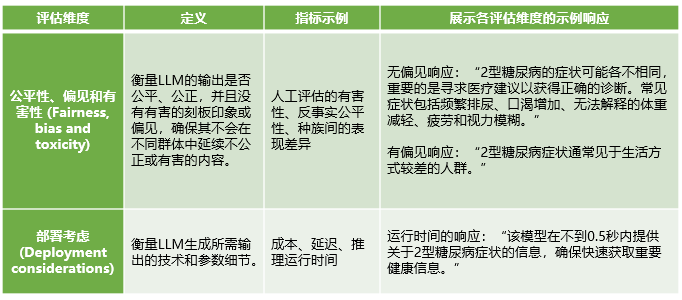
在亚专业测试方面,作者指出,不同亚专业之间LLM评估的不平衡现象。核医学、物理医学和医学遗传学等专业在LLM相关任务的研究中尤为不足。这种不平衡可能会影响LLM在特定医疗领域的有效性和适用性。因此,作者呼吁对不同亚专业中的临床任务进行全面测试,以确保LLM能够满足不同医疗领域的特定需求。
03
总结
本文强调了对LLM进行系统性评估的重要性,以及在真实世界数据上测试的必要性。作者呼吁建立一个持续的评估循环,其中模型被构建、实施,然后通过用户反馈不断评估。这对于改善医生的工作量和患者结果至关重要。通过这种方式,我们可以实现LLM在医疗领域的潜力,为临床实践带来真正的变革。
参考文献
JENELLE JINDAL , SUHANA BEDI, AKSHAY SWAMINATHAN, et al. Large Language Models in Healthcare: Are We There Yet?[Z/OL]. Stanford University Human-Centered Artificial Intelligence. [2024-5-8].https://hai.stanford.edu/news/large-language-models-healthcare-are-we-there-yet.
编辑:梨九
二审:且行
三审:清扬
排版:半夏
封面图源:金宝搏网站登录技巧
相关文章
评论

 我要跟帖
我要跟帖.jpg)



